
Architectures micro-services : objectifs, bénéfices et défis - Partie 2
Les architectures micro-services permettent de développer, de déployer et de gérer opérationnellement des applications distribuées, constituées de services aux fonctionnalités complémentaires, potentiellement hétérogènes et interopérables.
Ils favorisent drastiquement l'indépendance des cycles de vie, qu'il s'agisse des cycles de conception, de développement, ou de déploiement en production.
Les défis soulevés par les micro-services
Les avantages liés à l’utilisation de micro-services sont nombreux. Cependant la distribution des micro-services et leur nombre induit une nouvelle forme de complexité. En effet :
- L’approche nécessite un effort de conception et d'analyse fonctionnelle (cf. notion de contexte délimité) pour faire émerger des unités fonctionnelles autonomes et fortement cohésives.
- Elle nécessite également de prendre en compte des contraintes techniques d'intégration et de médiation de données (cycle de vie des interactions entre micro-services, méthodes de communication réseau, transactions à l’exécution de groupes d’opérations liées, ...)
- La gestion opérationnelle des micro-services est plus complexe, notamment en ce qui concerne le déploiement, les tests et le monitoring.
- L’approche nécessite enfin une organisation humaine compatible avec le système réalisé (cf. loi de Conway: "organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations" (**)).
(**) : En réponse à cette loi, l’approche inverse : "Inverse Conway maneuver" propose de faire évoluer l’organisation de l’entreprise pour promouvoir l’architecture cible.
Conway’s Law … can be summarized as “Dysfunctional organizations tend to create dysfunctional applications.” To paraphrase Einstein, you can’t fix a problem from within the same mindset that created it, so it is often worth investigating whether restructuring your organization or team would prevent the new application from displaying all the same structural dysfunctions as the original. In what could be termed an “inverse Conway maneuver”, you may want to begin by breaking down silos that constrain the team’s ability to collaborate effectively.
Etablir le périmètre fonctionnel d’un micro-service
L'approche Domain Driven Design développée par Eric Evans propose le concept de "contexte délimité" (Bounded Context). Selon cette approche, un domaine fonctionnel se caractérise par un langage interne, grâce auquel les différents intervenants se comprennent. Certaines des entités qui font l'objet de ce langage interne sont purement spécifiques au domaine fonctionnel considéré.
D'autres, au contraire, débordent de ce domaine fonctionnel et sont échangées et utilisées dans un autre contexte fonctionnel. Par exemple, un "client" ou un "produit" est une entité souvent transverse à plusieurs domaines métiers (Marketing, Inventaire et stocks, Finance). Selon cette approche, un domaine métier peut se décomposer en sous-domaines à l'intérieur desquels résident des entités internes au contexte (qui ne nécessitent pas d'être communiquées) et des entités échangées entre contextes. Les entités internes délimitent le domaine métier du contexte borné et permettent de concevoir le modèle sur lequel un micro-service est construit. Les entités échangées interviennent naturellement dans l'élaboration des interfaces entre micro-services.
Intégration des micro-services
Tout système distribué se doit de coordonner les interactions entre ses composants, et d’intégrer les réponses et les opérations effectuées par les différentes parties du système. C'est de cette coordination et de cette bonne intégration qu'émergent les fonctionnalités attendues. Voici quelques-unes des questions liées à l'intégration des services que ce type d'architecture soulève :
- La communication entre deux micro-services est-elle de nature synchrone ou asynchrone ?
- Quel niveau de cohérence de modèles de données doit être assuré entre micro-services ?
- Quel(s) protocole(s) d'échange faut-il préférer : SOAP, REST, Thrift, RPC, messaging, etc...
- Quel format utiliser pour le transport des informations : XML, JSON, binaire, etc...
- Comment gérer les cas d'exceptions techniques ?
Au final, ces choix dépendent des fonctionnalités à réaliser, chaque cas d'utilisation induisant des besoins spécifiques. Quelle que soit la forme d'intégration finalement choisie, il demeure crucial de préserver l’indépendance des micro-services, et de ne pas introduire de couplage technologique (par exemple, en imposant un langage unique dû au protocole de communication utilisé).
Les API REST, très flexibles et quasi-universellement supportées, rencontrent un grand succès pour l'implémentation des micro-services. Elles semblent devenir un quasi-standard pour leur intégration. Gestion de données distribuées Dans le cas d'applications de gestion développées selon un modèle monolithique, l'intégrité des données peut s'appuyer sur les mécanismes transactionnels internes aux bases de données relationnelles :
- La portée des transactions est démarquée explicitement dans le code ou à l'aide d'annotations.
- Le gestionnaire de transactions et la base de données garantissent que les opérations effectuées respectent les critères ACID avec divers niveaux d’isolation.
À contrario, dans le cas d'une application bâtie sur des micro-services, les données sont distribuées dans des magasins de données potentiellement hétérogènes. Les données sont usuellement encapsulées et propres à un micro-service, et accédées indirectement via une API. De plus, les magasins de données peuvent être de natures diversifiées (par exemple : relationnel, clé-valeur non relationnel, plein texte ...).
Certaines fonctionnalités peuvent demander des mises à jour de données distribuées, via des appels distants synchrones ou asynchrones. La coordination des modifications, ainsi que l'annulation en cas d'échec, ne sont pas assurées par un gestionnaire de transaction unique, et imposent des changements dans la gestion des modifications de données. Différentes approches peuvent être utilisées :
- Si possible, réunir toutes les opérations indissociables au sein d'un même micro-service de manière à bénéficier des caractéristiques ACID de la base de données sous-jacente.
- Garantir la transaction en s'appuyant sur un gestionnaire de transactions distribuées. Cette solution n'est en principe pas hautement extensible et comprend des risques pratiques de couplage technologique.
- Utiliser une architecture d’intégration "Event driven" en s'appuyant sur un broker de messages ou sur framework basé sur le modèle d'acteurs (Vert.X, Akka). Les mises à jour de données entre micro-services s’appuient alors sur la notion d'événement. Passer à un modèle de transactions « BASE ».
- Annuler les opérations qui produisent une incohérence à l'aide d'opérations de "compensation" éventuellement gérées par un administrateur ou par un programme "batch".
Communications synchrones et asynchrones
Il est bien évidemment possible d'implémenter des micro-services selon des modèles de communication synchrones. C'est parfois, effectivement, la solution la plus pratique, et les problèmes de disponibilité et d’extensibilité peuvent relativement facilement se régler grâce à la redondance. Cependant, il est souvent utile voire nécessaire d’utiliser une communication asynchrone pour accroître le découplage et gérer une communication par abonnements.
L'implémentation d'une architecture micro-services basée sur des communications synchrones peut devenir problématique dès lors que des micro-services invoquent récursivement un grand nombre de "sous-micro-services". C'est une forme de couplage fort, qui empêche l’extensibilité, et qui mène souvent à devoir utiliser des mécanismes de « circuit breakers ».
Representational State Transfer (REST)
REST, ou Representational State Transfer est un style d'architecture distribuée qui respecte les principes suivants :
- Architecture Client – Serveur : appels distants distribués au-dessus d'un réseau, favorisant le découplage et l’extensibilité.
- Protocole sans état : Le contexte relatif à l'état de la communication n'est pas conservé par le serveur entre deux requêtes. L'état de la session est conservé côté client.
- Mise en cache : Dans des communications réseau, les clients et les intermédiaires peuvent mettre en cache la réponse d'un serveur et optimiser ainsi les communications.
- HATEOAS (Hypertext As The Engine Of Application State) : Les serveurs peuvent répondre à une requête client en lui intégrant dans la réponse des liens hypermédia indiquant comment obtenir des fonctionnalités complémentaires.
REST est fréquemment utilisé pour la construction de tout ou partie d'une architecture micro-services car ce style d’architecture n'introduit pas de couplage technologique entre les composants. Le modèle de maturité développé par Leonard Richardson met en évidence les étapes de mise en œuvre de ce type d'API.
Style d'intégration
Les services mis en jeu pour dans un cas d'utilisation donné sont-ils orchestrés par un service de plus haut niveau? À priori, un service d'orchestration est une contrainte excessive, et il est généralement préférable d'opter pour des micro-services les plus autonomes possibles. Cela permet de préserver l'indépendance et le découplage des micro-services.
Toutefois, il est nécessaire d'utiliser des mécanismes de découverte automatique et d'indexation de services (registre), et potentiellement des services centralisés de configuration. La règle étant que les micro-services doivent à priori être conçus indépendamment de la connaissance de cette infrastructure, et ne doivent individuellement pas dépendre de ces services pour fonctionner. L'utilisation de la technique HATEOAS au-dessus de REST permet de bénéficier d’une infrastructure qui informe dynamiquement des changements d’URL et d’APIs.
Gestion des versions
Au fur et à mesure du temps et des évolutions du système, les interactions entre clients et serveurs évoluent. Une architecture micro-services doit gérer ce type d'évolution :
- Un client doit pouvoir évoluer tout en restant compatible avec un serveur qui n'a pas évolué.
- Un serveur doit pouvoir évoluer tout en continuant à accepter les requêtes en provenance d'un client qui n'a pas évolué.
Le pattern des "clients tolérants" ou "tolerant readers" favorise l’évolutivité des API REST. Il peut se résumer ainsi : “Design the client or service to extract only what is needed, ignore unknown content, and expect variant data structures.” Une approche pragmatique pour gérer la compatibilité entre client et serveur est d’utiliser le n° de version et de suivre les bonnes pratiques suivantes :
- Eviter et retarder le plus longtemps possible l’introduction de modifications ayant un impact sur les interfaces
- Utiliser la convention de version sémantique : MAJOR.MINOR.PATCH. Cette information de version peut, par exemple, se communiquer dans les en-têtes HTTP d'une requête REST.
- Mettre en pratique la loi de Postel, ou principe de robustesse côté serveur : "Be conservative in what you do, be liberal in what you accept from others."
Il est également possible d'utiliser une approche de type Consumer Driven Contract afin de détecter le plus en amont possible les incompatibilités entre services et clients induites par une modification. Dans cette approche, le client réalise des tests d'intégration qui expriment ses attentes vis-à-vis de l’API de services. Ces tests sont fournis par le client et incorporés dans la collection de tests du service.
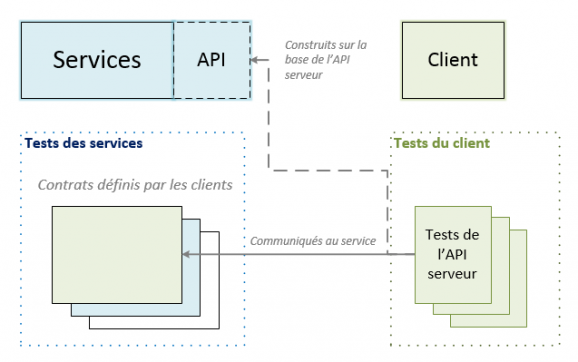
Le « Consumer Driven Contract » est supporté par le framework Pact.
Tests des micro-services
Le test des applications micro-services doivent être automatisés et associés au processus d’intégration et de déploiement (cf. approche de Production Continue ou « Continuous Delivery »). Un micro-service étant autonome et indépendant, il est potentiellement déployé individuellement lorsque les tests sont concluants. Dans une architecture micro-services, le plus complexe est de tester le comportement d’un ensemble de micro-services. Cela nécessite d'initialiser le micro-service à tester, ainsi que les micro-services liés, ou d'écrire des doublures de tests pour isoler le service à tester. Pour résumer les enjeux des tests de micro-services par rapport à ceux d'applications monolithiques :
- Ecrire des tests est plus coûteux et plus complexe lorsqu'on teste le fonctionnement intégré d'un ensemble de micro-services. Il faut potentiellement déployer et préparer plusieurs jeux de données de tests et démarrer plusieurs processus;
- Le développement et le déploiement de micro-services peut se coupler à l'écriture des tests, ce qui permet d'implémenter des pratiques de déploiement continu.
Obstacles à la testabilité des micro-services
Compte tenu du nombre de services déployés dans une architecture constituée de micro-services, il peut être difficile de recréer un environnement de production complet pour les tests. De plus, les micro-services sont fréquemment intégrés via des communications asynchrones. Les communications asynchrones découplent temporellement les interactions entre micro-services, mais ajoutent également à la complexité des tests (le délai nécessaire à la propagation d’un événement devant être pris en compte dans les scénarios de test). Dans un tel contexte, il est difficile d'être certain que les tests couvrent effectivement toutes les subtilités de l’environnement de production.
Tester? Ou favoriser le monitoring?
Bien qu'il soit effectivement important de qualifier le fonctionnement de micro-services par des tests dans le but de déployer plus rapidement, il est difficile de garantir qu’aucun effet de bord n’est induit par une mise à jour. Il est donc nécessaire de compléter les tests par un effort de monitoring permettant de déceler rapidement des anomalies de production. Un retour en arrière ou une mise à jour corrective peuvent alors être rapidement décidés en vue de maintenir le bon fonctionnement de l'application.
Gestion des déploiements
Automatisation du développement et du déploiement
La mise en œuvre d'une architecture micro-services démultiplie le nombre de livrables à déployer. La gestion des livrables devient une tâche complexe qui doit être intégralement automatisée. Cette automatisation passe par la maîtrise de la chaîne de production logicielle, des tests et des déploiements. C’est objet de l’approche de « Production Continue » ou « Continuous delivery » qui inclut notamment :
- La gestion de configuration
- La construction des livrables
- La virtualisation des environnements et le « provisionning » des infrastructures
- L’automatisation des modifications de schéma
- L’automatisation des tests
- L’automatisation des déploiements
- Le suivi de l’ensemble de la chaîne
La ligne de production logicielle doit être apte à gérer les incréments de version automatisés mais aussi les retours en arrière. Une large palette d’outils existe pour y parvenir, dont le choix dépend du langage, du système et des technologies utilisés par le projet.
- Git, Mercurial, Gitlab – Gestion de configuration décentralisée
- Ansible, Salt – Provisionning automatisé de machines virtuelles
- Docker – Virtualisation d’environnements
- Maven, Gradle - Outils de construction de livrables et de gestion des dépendances
- Artifactory, Nexus – gestion d’artefacts et de dépôts
- Bintray – publication de packages open source
- Flyway, Liquibase – mise à jour automatisée de schémas
- Kong combiné à Nginx – gestion centralisée d’API REST pour fournir des fonctionnalités transverses telles que le contrôle de charge, l’authentification ou les traces
- Jenkins, Bamboo - serveurs d’intégration et de déploiement continu
- Cucumber - framework de test orienté comportement (BDD)
- Arquillian - framework de test d’intégration
- …
La liste des outils et technologies qui peuvent entrer dans la construction d’une ligne de production automatisée présentée ci-dessus est bien entendu loin d’être exhaustive.
Technologies de virtualisation d'environnements
De nombreuses technologies très prometteuses ont récemment vu le jour dans le domaine de la virtualisation d'environnement :
- Docker: Technologie de virtualisation d'environnement permettant d’encapsuler l’application et ses dépendances système dans un conteneur virtuel, assurant ainsi son isolation et la maîtrise de son comportement vis à vis de son environnement d'exécution.
- Kubernetes: Plateforme d'automatisation de déploiement de conteneurs Docker, permettant de redimensionner dynamiquement le besoin et d'ajuster les ressources physiques utilisées.
- MesOS: Système de gestion de grilles de machines virtuelles permettant de gérer les ressources (CPU, mémoire et stockage) dynamiquement à l’échelle du data center.
- CoreOS: Système d'exploitation minimaliste conçu pour être opéré en cluster, avec un support natif pour les technologies de conteneurs (système similaire à RancherOS).
Docker est un outil essentiel dans cet écosystème car il permet d’isoler efficacement les micro-services, de fiabiliser la gestion de l’environnement d’exécution des applications et de faciliter les tests et le déploiement. Les autres technologies répondent à des besoins qui apparaissent au fur et à mesure que le nombre de services et la charge augmentent. Kubernetes permet de gérer l’isolation des conteneurs Docker dans un réseau virtuel, et de déployer des conteneurs Dockers sur plusieurs plateformes. Des solutions commerciales telles que Giant Swarm permettent de réduire le coût de mise en place d'une telle infrastructure.
Monitoring des micro-services
Dans un contexte de micro-services, le monitoring a plusieurs objectifs :
- Surveiller le bon fonctionnement de l'infrastructure;
- Surveiller le fonctionnement des appels entre micro-services;
- Surveiller le respect du niveau de service (SLA -Service Level Agreements);
- Cartographier dynamiquement la répartition des micro-services sur l'infrastructure et les versions de services déployées
Le monitoring de l'infrastructure, au sens large, peut s'implémenter en combinant Kibana, ElasticSearch, LogStash :
- Kibana: Plateforme de visualisation graphique de données, que nous spécialisons dans notre cas particulier sur les logs systèmes (ou tout autres logs pertinents).
- ElasticSearch: Moteur de recherche distribué accessible via REST/JSon.
- Logstash: Outil d'agrégation de données ou de logs, extensible à des formats de logs personnalisés sur mesure.
Splunk est une solution commerciale concurrente. Implémenter le monitoring du flux de requêtes/réponses entre micro-services nécessite souvent une instrumentation des appels de manière à réconcilier le flux de requêtes/réponses :
- Stack Netflix: Servo permet d'instrumentaliser et d'exposer, depuis l'intérieur d'un micro-service, les données souhaitées. Différents modes de récolte de ces données (jauges, compteurs, timers, etc...) sont disponibles, ainsi que la possibilité de les exposer à des clients tels que Netflix Atlas, ou, dans un contexte commercial, à des services tels que Amazon CloudWatch.
- Stack Twitter: Zipkin est un système de traçage, déployable dans Docker, permettant d'agréger les temps de latence entre les différents micro-services. Les micro-services doivent, pour être monitorés, être préalablement instrumentés par la librairie Twitter Finaggle.
Cas d’application de ce style d’architecture
L’opportunité de mise en œuvre d’une architecture micro-services nécessite une analyse et une réflexion approfondie. C'est en effet la source d’une complexité opérationnelle accrue qui peut se justifier par l'efficacité que l'approche induit sur la durée. Voici quelques exemples qui justifient l’adoption de ce style d’architecture :
- La taille de l'équipe qui réalise le système est trop importante pour collaborer efficacement sur un monolithe;
- Les métiers concernés doivent impérativement évoluer indépendamment ;
- L’extensibilité (ou « scalabilité ») du système est primordiale et concerne certains services applicatifs plus fortement sollicités ;
- Le système monolithique équivalent devient trop complexe pour continuer à évoluer raisonnablement vite
Auteurs : Eric Manuguerra, Directeur Technique, et Guillaume Yziquel, Développeur Java/Angular JS, SQLI Suisse