
Et pourquoi pas du scaffolding pour accélérer les POC ?
Dans un contexte de développement logiciel, le scaffolding est le nom donné aux outils utilisant des templates de génération de code pour construire une application à partir d'un modèle en entrée. En fonction de l'outil et des technos, le code généré couvre différentes couches
Le terme scaffolding se traduit en français par "échafaudage". En paraphrasant, il s'agit donc de monter une structure rapide, simple et temporaire, qui va nous aider à la construction définitive.
Dans un contexte de développement logiciel, le scaffolding est le nom donné aux outils utilisant des templates de génération de code pour construire une application à partir d'un modèle en entrée. En fonction de l'outil et des technos, le code généré couvre différentes couches :
- L'IHM
- La couche service et le domaine métier
- La couche de persistance
- Le schéma de base de données
Du fait même de l'utilisation de templates, le résultat sera toujours une application généraliste, standard. La plupart du temps cette application simplement propose les opérations CRUD[1] de base des différentes entités. On fait souvent référence à Rails comme exemple de scaffolding. Il faut aussi citer Yeoman (npm install -g yo) dont la solution généralisée a permis la prolifération de générateurs d'applications web pour tous les langages.
Illustration du scaffolding avec JHIPSTER

Ce que propose le scaffolding est très prometteur mais aussi sujet à beaucoup de questions. La génération de code n'a jamais eu très bonne presse et on préfère toujours l'utilisation de librairies voire de frameworks, pour de bonnes raisons d'ailleurs. J’ai pu confronter ce postulat lors d’un essai, dont je vous livre mes retours.
Contexte
À la suite d’un hackathon au sein de SQLI, mes collègues et moi-même avons rapidement prototypé l'application que nous avions imaginée. Nous nous sommes tournés vers JHipster qui nous propose de générer une application standard avec des technologies "état de l'art" du moment (mais pas trop) : Spring boot et Angular JS. Nous connaissions la stack[2] et avons pu la modifier.
Conception et premières générations
Avec JHipster, on peut générer une application en s'appuyant sur un fichier texte décrivant le domaine métier. Ce fichier, au format JDL, définit les entités du point de vue données et leurs relations. Le format JDL (purement spécifique à JHipster, ressemblant un peu à Java) est très simple à utiliser. Il y a même un éditeur en ligne avec une interface plutôt sympathique, et une documentation… pas toujours complète malheureusement.
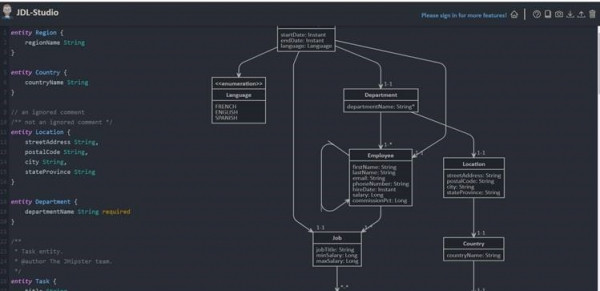
L'éditeur en ligne de fichiers JDL, avec une représentation graphique du modèle.https://start.jhipster.tech/jdl-studio/
Nous avons ainsi décrit le modèle de données que nous avions en tête, exporté le fichier JDL et lancé la génération… le serveur s’est lancé et nous avons immédiatement eu accès aux pages CRUD correspondant à notre modèle. Et là, tous les défauts de conception, les oublis, les mauvais nommages sont clairement apparus. Pas de souci : suppression de l'application, modification du fichier JDL, et relance de la génération n’ont pris que quelques minutes.
La troisième itération fut la bonne, nous avons ainsi pu commencer à coder !
Et là on parle de coder de la valeur ajoutée : tout le code boilerplate[3] a été auto-généré par l'outil, nous avons pu nous concentrer immédiatement sur la création de valeur. Super pour le moral.

Pour la génération du squelette de l'application, JHipster propose de nombreuses options et alternatives via la console.
Prise en main de l'application
Après environ 4 heures de travail, nous avons obtenu :
- Les pages CRUD pour chaque entité, en HTML et CSS (Bootstrap) + Angular
- Une couche exposant les services REST (SpringBoot : @RestController) de base nécessaires à l'application AngularJS
- Une couche service Java (SpringBoot : @Service)
- Une couche domain en POJO (SpringBoot : @Entity), avec les annotations qui assurent le mapping JPA
- Une couche de DAO (SpringBoot : @Repository) en JPA
- Une base de données locale H2SQL, dont le schéma est généré par Hibernate
Mais aussi :
- Un module IAM, avec les pages d'administration des utilisateurs et de leurs droits, la gestion des mots de passe, etc. La couche service de l'application est branchée (via Spring security) à ce référentiel.
- Un module d'audit des performances (JMX)
- Un module Swagger qui présente l'API REST
- Un module d'admin de la base de données de développement (HSQL fichier)
- Un système de logs
- Un système d'envoi de mails formatés
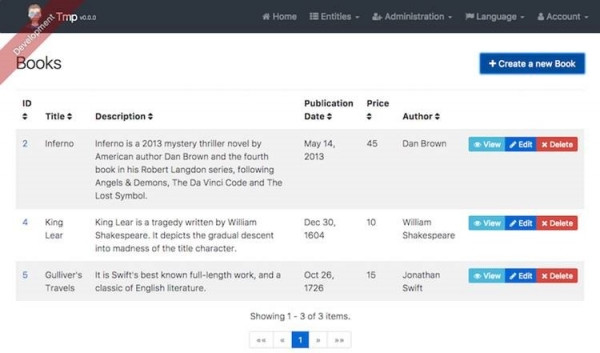
Un exemple brut de page de liste générée automatiquement. On peut très facilement enrichir la page et modifier la CSS, tant qu'on reste dans Bootstrap.
Pour notre prototype, nous n'avions besoin que de quelques pages pour les utilisateurs. Pour l'administration, nous nous sommes contentés au début des pages CRUD générées.
Un UX designer de la maison a maquetté avec nous 3 pages stratégiques et proposé quelques améliorations CSS.
Comme je l'ai expliqué, nous connaissions déjà la stack, et la mise en pratique des changements est plutôt simple. Le code généré par JHipster étant très propre et très compréhensible, la structure pour les Tests Unitaires fut prête. Toutes les bonnes pratiques classiques furent respectées.
Le déploiement
Au bout de deux jours de travail, les 3 pages remaniées et le prototype furent prêts à être déployés. JHipster a généré un POM qui décrit plusieurs profils de build. Avec un mvnw package -Pprod, nous obtenons un fat jar[4] pouvant être déployé et fonctionnant avec une base de données externe. Le reste n'est plus qu'une question de paramétrage et de configuration, principalement au travers des modules inclus par JHipster (IAM).
Il est à noter que si nous avons choisi les briques techniques les plus courantes (Maven, Angular, monolithe, fat jar), JHipster propose de nombreuses alternatives : Gradle, Docker, AWS Beanstalk, microservices, React, … que nous nous sommes promis de tester par la suite.
Les évolutions
C'est bien sûr là que la génération de code est attendue au tournant. Une fois le code généré, nous l'avons modifié pour l'enrichir et aller au-delà d'une application CRUD. Nous ne pouvions donc plus bénéficier des facilités du scaffolding.
Avec JHipster, le code généré ne l'a pas été avec l'idée de pouvoir le modifier automatiquement (« Insérez le code métier entre les balises, le reste sera écrasé »). L'outil a au contraire généré une structure d'application nette, prête à être reprise par un développeur humain.
Avec la bonne connaissance des technologies de la stack, nous avons procédé à ces évolutions dans un cadre très propre et très bien structuré.
Le boost de productivité du démarrage passé, on revient à un cycle et un rythme de développement classique.
Il est à noter que JHipster permet de regénérer uniquement les fichiers liés à une entité en particulier qui aurait été modifiée. Dans les faits, ça a fonctionné pour nous, mais pas à chaque fois. Et quand ça n'a pas bien fonctionné, il y a du travail pour nettoyer. Donc No Go pour nous de ce point de vue.
Un gain de temps certains, mais pas que
Dans le cadre de la création d’une application en un temps éclair, l'utilisation de JHipster était tout à fait appropriée. En quelques jours, on peut déployer un prototype avec des bases solides, prêt à évoluer grâce à :
- Une stack connue (Bootstrap, Angular, Spring boot)
- Une structure du code propre et standardisée
- Des modules déjà codés et intégrés (IAM, audit, …)
- Des pages CRUD d'administration brutes
- Les configurations de Maven, Liquibase, JUnit déjà écrites et bien organisées
Le scaffolding nous a facilement fait gagner du temps (2 à 3 jours sur les 4 passés à la réalisation de notre POC). Il permet de générer une application de base en quelques heures, et de se concentrer ensuite sur le développement des fonctionnalités porteuses de valeur. Au-delà du simple gain de temps, c'est aussi beaucoup plus intéressant pour toute l'équipe !
Nous avons même découvert certaines librairies ou bonnes pratiques, la stack de JHipster étant vraiment à jour et bien implémentée.
L'expérience du scaffolding fut donc une très bonne surprise. Par extension, il nous semble que ce pourrait être un outil parfait pour démarrer des projets plus ambitieux, et les gains seraient encore plus importants. La première génération pourrait même se rapprocher d'un walking skeleton[5] de sprint 0.
[1] CRUD
C'est l'abréviation des 4 opérations de base de persistance pour une entité : Create, Read, Update, Delete. Dans notre cas, ces opérations permettent par exemple de gérer un jeu de tests, de gérer des éléments de configuration, ou d'administrer simplement certaines données, sans trop de règles métier.
[2] Stack
La stack, dans notre contexte, est l'empilement des composants logiciels qui forment l'application. On parle d'empilement car on les représente souvent du bas (le cœur du SI, par exemple le serveur de base de données) vers le haut (l'autre bout… par exemple le poste utilisateur).
Pour faire propre, on organise ces composants par couches, elles aussi empilées.
Un développeur "full stack" est donc en théorie capable d'intervenir seul sur l'ensemble de ces composants.
[3] Boilerplate
C'est ainsi qu'on qualifie le code récurrent, qu'il faut réécrire régulièrement, et donc sans grande valeur ajoutée. Par exemple la recopie d'un objet métier dans un DTO, et inversement, ou les getter et les setter d'un objet Java, ...
[4] Fat jar
C'est le fait d'inclure dans le package (jar) toutes les dépendances nécessaires au fonctionnement de l'application, y compris le serveur web (Tomcat par exemple).
Il suffit alors d'avoir à disposition un serveur avec la bonne version de JVM, et le déploiement devient ainsi beaucoup plus simple.
[5] Walking skeleton
C'est une implémentation minimale, mais entièrement fonctionnelle, de l'architecture logicielle qu'on souhaite mettre en place. Typiquement le genre de chose à atteindre en fin de sprint 0.