
Comment mettre en place Kubernetes ? Partage d’expérience de devs
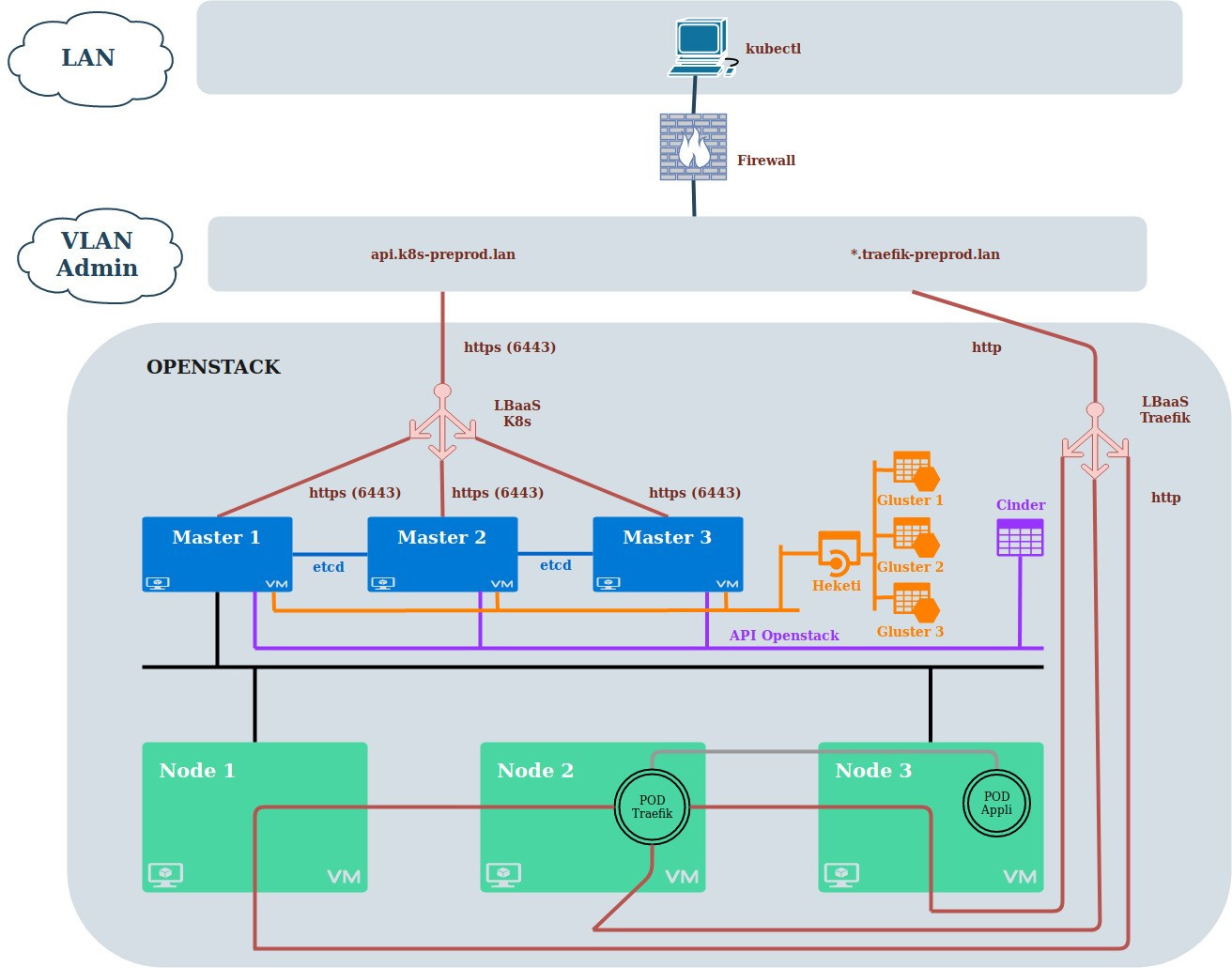
A travers cet article, nous allons partager avec vous, l’activité et les notions associées au sein de l’équipe, nos découvertes et nos interrogations sur l’ensemble des couches technologiques associées à Kubernetes. En nous suivant, vous comprendrez le schéma suivant !
Tout a commencé par un défi lancé par nos OPS… « Kubernetes, c’est si facile à mettre en place dans notre cloud privé que vous pourriez y arriver sans nous ! » Nous avions alors répondu : « Challenge Accepted ! ». Qui sommes-nous ? Des développeurs, l’un orienté BI/DATA et l’autre PHP/JAVA, avec une appétence non dissimulée pour ce qui est système. Avec nos deux administrateurs système, nous avons créé il y a quelques années une équipe de moyens de production en charge du maintien et de l’évolution de notre plateforme de production interne.
Au fait, pourquoi Kubernetes ?
Kubernetes (k8s) s’inscrit dans la continuité de la mise en place de notre cloud privé Openstack qui expose un ensemble de services dont :
- La gestion des ressources (CPU/RAM/Stockage), des gabarits de déploiement, un repository d’images de référence à déployer
- La gestion du réseau (VLAN, load balancer, …)
Nous souhaitons garantir la reproductibilité à grande échelle de nos environnements virtualisés, parfois au détriment de leur maintenabilité. La plateforme Openstack propose pour ce faire des API REST. Il devient alors possible de bénéficier d’un framework qui permet d’administrer le cloud via des scripts. Nous parlons ici d’« infrastructure as code ». Kubernetes étant un cluster découpé en un ensemble de services, chaque service/composant du cluster fonctionne dans une image docker. Le cluster fonctionne selon une architecture classique :
- Une orchestration de services gérée par des masters et des workers (en charge du déploiement des services autres que ceux du cluster lui-même, ceux du client final) :
- Un master s’apparente à un API Server qui va permettre aux différents composants de communiquer à l’intérieur d’un Cluster Kubernetes
- Un node (appelé aussi worker) est le plus souvent une machine virtuelle (VM) qui héberge des services
- Un client kubectl permettant d’administrer le cluster depuis son poste de travail
- Chaque service est redondé sur au moins 3 masters afin de garantir un quorum (gestion des indisponibilités et de la répartition de charge). Si une panne survient il est nécessaire de garantir la tolérance à la panne, donc de posséder au minimum 2 masters.
- Il est conseillé de positionner les masters sur des sites géographiques différents pour obtenir une meilleure tolérance de panne si un site devient inaccessible. Dans l’idéal, nous devrions pouvoir mettre un master sur les 3 sites correspondants aux 3 centres de services SQLI (Nantes, Bordeaux et Maroc), mais pour des raisons de simplification, nous avons dans un premier temps choisi de tout installer sur notre instance de préproduction localisée à Bordeaux.
- Les problématiques de mise en place sur 3 sites différents sont multiples, que ce soit les interactions réseaux ou la réplication de données dans un cluster Openstack. Ces points seront présentés ultérieurement.
Création des masters et de nodes
Pour le fonctionnement de Kubernetes, nous avons donc besoin de masters et de nodes. Mais sur quel OS vont se baser ces VM ? CoreOS est basé sur un noyau Linux. Son poids léger (<300Mo) garantit une empreinte minimisée, ce qui permet un déploiement plus rapide. Cette distribution Linux possède une gestion native des containers Docker. CoreOS a été conçu pour :
- Le déploiement d’infrastructures dédiées à la gestion de services fonctionnant sous Docker
- La mise en place facilitée de haute disponibilité notamment grâce à l’intégration native d’une base de données ETCD (clé/valeur)
Le déploiement d’une machine virtuelle CoreOS sur le cloud privé Openstack s’intègre complètement dans le principe « everything as code » car il propose un mécanisme d’initialisation à l’aide d’un script appelé « cloud-config ». Pour provisionner les VM (3 masters et 3 nodes), nous utilisons Ansible. Il s’agit d’un outil de déploiement descriptif, c’est-à-dire que les actions de déploiement sont décrites dans un fichier au format YAML et qu’aucune action manuelle n’est nécessaire pour effectuer les installations. L’exécution de nos scripts Ansible nécessite d’avoir accès à un compte d’administration de notre plateforme Openstack.
Déploiement de Kubernetes
Nous avons choisi d’utiliser Kubespray pour le déploiement de notre cluster Kubernetes sur notre plateforme Openstack. Le déploiement se déroule également à partir de scripts Ansible. Il est nécessaire de fournir à Kubespray les fichiers de configuration suivants :
- yml : les références liées à l’environnement Cloud cible (URL, compte, etc.)
- ini : les adresses IP liées aux masters et nodes où doivent se déployer les composants Kubernetes
- Un certificat pour authentifier les futurs appels aux API
Kubespray ayant son propre cycle de vie, nous avons dans un premier temps fixé la version 2.8.0 comme version à installer sur nos environnements. Des tests sont à venir sur une montée de version en 2.8.3. Les autres outils de déploiement de Kubernetes ne proposant pas de scripts Ansible pour le déploiement sur Openstack, nous nous sommes limités à l’utilisation de Kubespray. L’installation n’a pas posé de problème majeur, excepté une mise à jour de la configuration DNS sur les masters et nodes. DNS (Domain Name System) est le service qui permet de faire le mapping entre une URL et une adresse IP.
A présent, place au déploiement d’applications !
Nous avons enfin une plateforme opérationnelle et allons donc pouvoir déployer une application. Il faut dans un premier temps expliquer ce qu’est un pod :
- Il constitue l’entité de base que l’on déploie et manage dans un cluster Kubernetes
- Il regroupe un ou plusieurs conteneurs (le plus souvent Docker)
- Il partage entre ces conteneurs des namespaces (~ressources) et des volumes
Commençons simplement en installant un serveur Nginx à partir d’une image Docker. Vous avez maintenant l’habitude, la configuration se fait dans un fichier YAML. La création se fait via une ligne de commande à l’aide d’un client kubectl installé sur notre poste de travail (et qui pointe sur le cluster Kubernetes). Ce fichier YAML est constitué de 2 parties :
- ReplicationController : description de la configuration de l’application.
- Service : description de l’exposition (interne et/ou externe) de l’application sur le réseau. Sans service, une application déployée est inaccessible.
Avec un pod désormais créé à l’aide d’une adresse IP aléatoire dans notre cluster Kubernetes, nous souhaitons désormais y accéder depuis une URL.
Traefik à la rescousse
Petit problème ! Si l’IP est aléatoire lors de la recréation d’un pod ou de la duplication de ce pod (scalabilité), il faut mettre en place un proxy pour avoir une URL qui pointera toujours sur la bonne IP. Traefik est notre choix pour répondre à cette problématique. Ce reverse-proxy est le point d’entrée pour les différents flux à destination des services hébergés dans le cluster Kubernetes. On obtient un frontal HTTP / HTTPS qui donne accès aux services via des URL (sans connaissance des ports). Les items sont :
- URL : ce sont elles que va connaître Traefik (utilisées depuis les navigateurs), celles qui sont référencées vont correspondre à des backends
- Backend : correspond à la corrélation entre une IP interne au cluster Kubernetes et le port sur lequel tourne un Pod Kubernetes (coordonnées du service)
Cela revient à dire que l’ensemble des flux à destination de Kubernetes arrive sur un point d’entrée unique. Traefik sait, pour chaque URL qui arrive et vers quel backend envoyer le flux. L’accès se fait donc côté client via une URL sans spécifier de port. Cela permet également de ne pas déclarer de LoadBalancer pour chaque service à déployer (une seule IP frontale au lieu d’une par service de type LoadBalancer). Il est tout de même nécessaire de définir la wild card '*.wild.card.com' pour accéder à l’application myapp.wild.card.com. Cette configuration s’effectue via un serveur DNS interne. Hormis pour la partie Réseaux, nous avons été relativement autonomes grâce à notre accès "Administrateur" de la plateforme Openstack. L’installation de la plateforme aura permis de nous familiariser avec l’ensemble des notions techniques nécessaires à l’utilisation d’un cluster Kubernetes, que nous avons partagé avec vous aujourd’hui. Dans un prochain article, on évoquera la partie Stockage ! Article écrit par :
- Eric Terrien, Expert technique
- Rodolphe Baron, Expert technique
- Romain Ballan, Ingénieur Systèmes & Réseaux